
JavaScript, alongside HTML and CSS, is considered a core technology for building web content. As an influential scripting language found nearly everywhere on the web, it provides several unique vulnerabilities for malicious developers to attack unsuspecting users and infect otherwise legitimate and safe websites. There is a clear and eminent need for users of the web to be protected against such threats.
Methodologies used for the judgment of JavaScript safety can be separated into two broad categories: static and dynamic. Static analysis of JavaScript will treat the textual information in the script as the sole source of raw data. Computation can take place on this text to calculate features, estimate probabilities and serve other functions, but no code is ever executed. On the other hand, dynamic analysis will include evaluation of the script through internet browser emulation. Varied by the complexity and breadth of emulation, this has the potential to provide much more insightful information about the JavaScript’s true functionality and, thus, safety. However, this comes at the cost of increased processing time and memory usage.
“Obfuscation” is the intentional concealing of a program’s functionality making it difficult to interpret at a textual level. Obfuscation is a common problem for static analysis; dynamic analysis is much more effective at overcoming obfuscation. Minor obfuscation can include things like random or misleading variable names. However, heavier amounts of obfuscation aren’t so simple. Here is an example of a heavily obfuscated script, abridged for brevity:
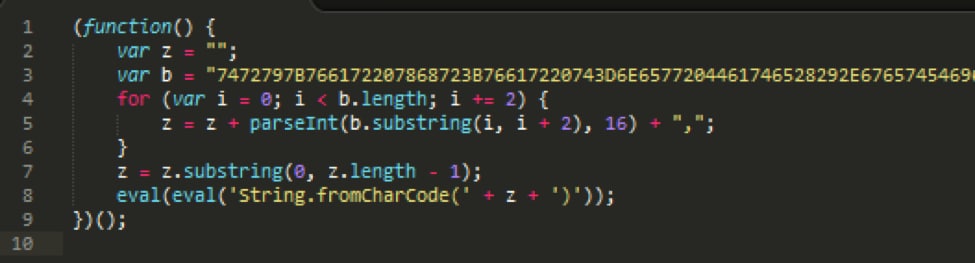
As you can see, there is no way to infer the script’s functionality from a textual standpoint. Here is the original script, before obfuscation:
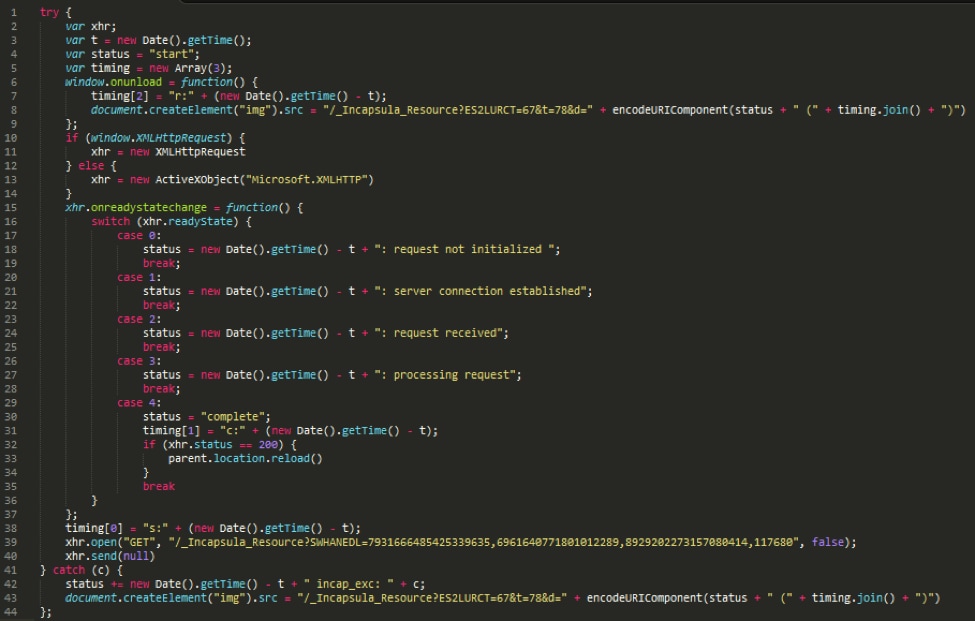
A human can easily interpret this original script, and there is much more readily available information about its level of safety. Note that, textually, the obfuscated and original scripts look almost nothing alike. Any text-based features extracted from the two files would likely look completely different.
It is important to note that both benign and malicious developers use obfuscation. Well-intentioned developers will often still obfuscate their scripts for the sake of privacy. This makes the automatic detection of malicious JavaScript tricky since, after a script has been obfuscated, malicious and benign code can look nearly the same. This problem is pervasive. In a randomly sampled set of 1.8 million scripts, approximately 22 percent used some significant form of obfuscation. However, in practice, we’ve found the use of obfuscation to be largely disproportionate between malicious and benign developers. In a labeled sample of about 200,000 JavaScript files, over 75 percent of known malicious scripts used obfuscation, while under 20 percent of known benign scripts used it.
A natural concern arises for traditional machine learning techniques, trained on hand-engineered, static textual features generated from scripts, to unintentionally become simple obfuscation detectors. Indeed, using the presence of obfuscation as a determining factor of maliciousness wouldn’t give you bad results in any evenly distributed dataset. Accordingly, heavily weighting the presence of obfuscation is a likely result of training algorithms to improve accuracy. However, this is not desirable. As mentioned, legitimate developers use obfuscation in a completely benign manner, so obfuscated benign samples need to be rightfully classified as benign to avoid too many false positives.
Static Analysis
Extracting Hand-Engineered Features
Despite these challenges, we’ve found the use of static textual features still has the potential to perform well. Our experiments suggest static analysis can produce acceptable results with the added benefit of simplicity, speed and low memory consumption.
Our experiments took place on approximately 200,000 scripts, around 60 percent of them benign and the other 40 percent malicious. This skew in the distribution was intentional. In any natural sample taken from crawling the internet, the percent of scripts that are malicious would be around 0.1 percent, whereas in our training set we are using 40 percent malicious samples. If we trained with the natural 0.1% distribution we would have problems with our results. For example if you created a classifier that always said “Benign” it wouldn’t be very useful, but it would be right 99.9% of the time!
Using a training set with more malicious samples than benign samples runs the risk of developing an obfuscation detector, since most malicious samples are obfuscated. If they represent most of the dataset, obfuscation will likely be learned as a strong predictor to get good accuracy. We instead introduced a distribution only slightly skewed toward benign samples, which forces the model to learn to better detect benign samples without overpowering the need to detect malicious samples. This also maximizes the amount of obfuscated benign samples, which we are particularly concerned with and want to train on as much as possible.
Here is a visualization of a uniformly selected, random sample of our 128-dimensional data:
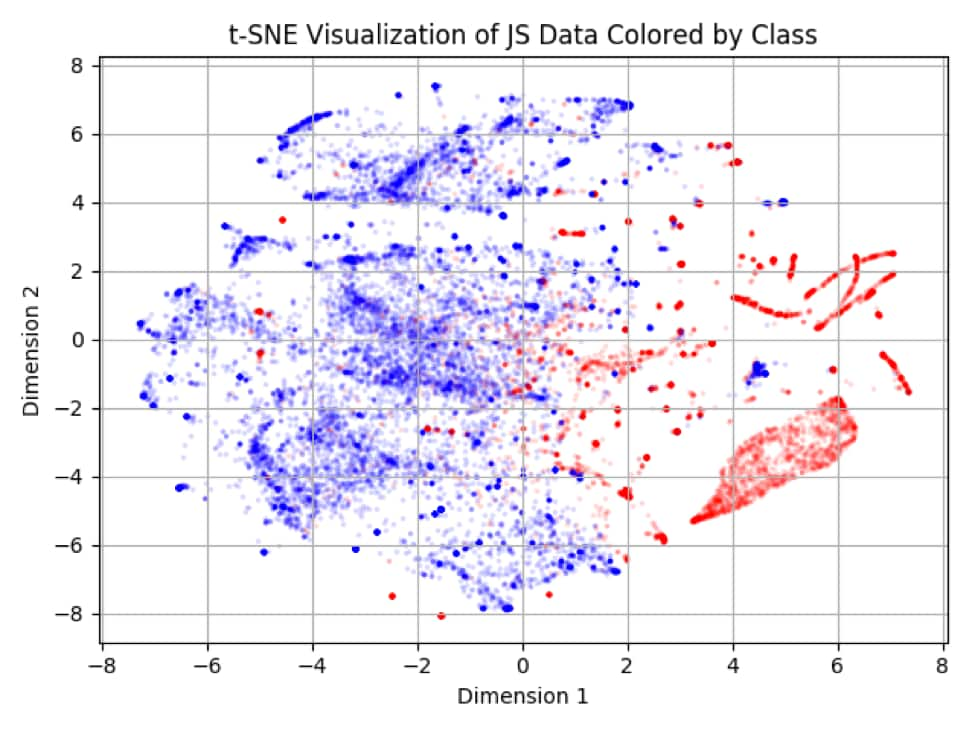
In the visualization, blue is benign and red is malicious. Although it’s not perfect (as is the case with any real-world data), notice the local separability between the benign and malicious clusters. This approximated visualization, created using the technique known as t-SNE, was a good omen to continue our analysis.
With a 70 percent training and 30 percent testing split, a random forest with just 25 trees could achieve 98 percent total accuracy on the test set. As mentioned before, test set accuracy is not always very informative. The more interesting numbers attained are the 0.01 percent false positive rate and the 92 percent malicious class recall. In English, this means only 0.01 percent of benign samples were wrongly classified as malicious, and out of the entire pool of malicious samples, 92 percent of them were correctly detected. The false positive ratio was manually decided by adjusting the decision threshold to ensure certain quality standards. The fact that we maintained 92 percent malicious class recall while enforcing this low false positive ratio is a strong result. For comparison, typical acceptable malicious class recall scores fall between 50 and 60 percent.
We hypothesize that certain obfuscation software is more commonly used among benign developers than malicious developers and vice versa. Aside from the fact that randomly generated strings will all look different anyway, more interestingly, certain obfuscation techniques result in code that is structured differently from other obfuscation techniques at a higher level. Distributions of characters will also likely change with different obfuscation methods. We believe our features might be picking up on these differences to help overcome the obfuscation problem. However, we believe there is a much better solution to the problem, which we will detail here.
Composite Word-Type Statistical Language Model
As opposed to hand-engineered feature extraction, a more robust and general approach to go about static analysis on text files is to build statistical language models for each class. The language models, which for simplicity’s sake can be thought of as probability distributions, can then be used to predict the likelihood of scripts to fit in that class. Let’s discuss a sample methodology to build such a system but many variations are possible.
The language model can be defined over n-grams to make use of all information in the script. More formally, we can write a script as a collection of J n-grams as such (the value of n is unimportant):
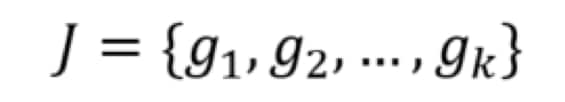
Then, we can build a malicious class model, script M, and a benign class model, script B. The weight of each n-gram for both models can be estimated from the data. Once these weights are determined, they can be used to predict the likelihood of a script belonging to either class. One possible way to measure these weights from a set of scripts all belonging to the same class is simply to calculate the number of times that n-gram appears in all scripts in the set over the total number of n-grams found in all scripts in the set. This can be interpreted as the probability of an n-gram appearing in a script of a given class. However, because of the effects of naturally common n-grams being weighted heavily in both classes despite being uninformative, one may instead seek out a measurement such as term frequency-inverse document frequency. TF-IDF is a powerful statistic, commonly used in the domain of information retrieval, that helps alleviate this problem.
Once the language models have been defined, we can use them for the sake of calculating the likelihood of a script belonging to either class. If your methods of model construction build the model as a probability distribution, the following equations will do just that:
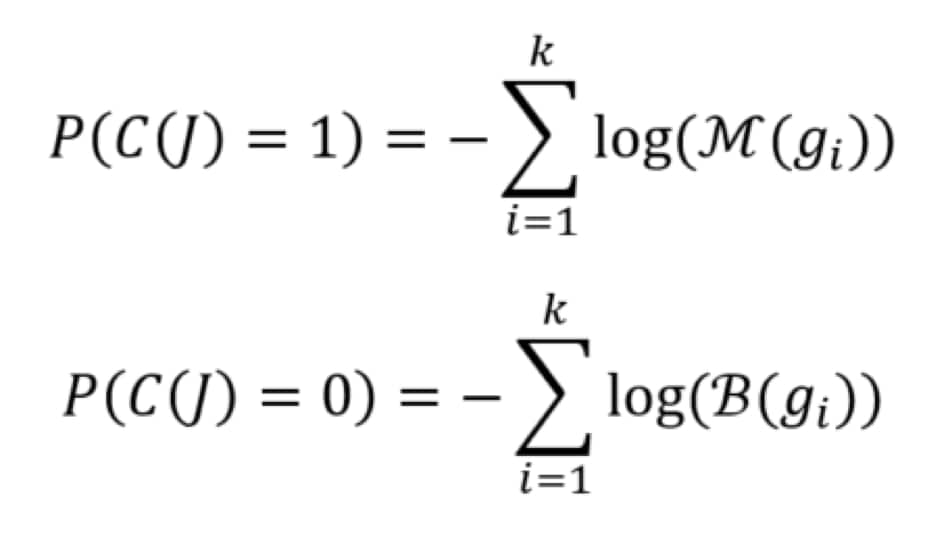
In the above, C(J) represents the true class of J, which is either 0 or 1 for benign and malicious respectively. The class with the highest probability can be chosen as the predicted class. A different variation entirely could be to use the weights of n-grams as features to calculate a feature vector for each script. These feature vectors can be fed into any modern machine learning algorithm to build a model that way.
However, note that the space of possible n-grams in JavaScript code is massive; much larger than standard English text. This is especially true in the presence of obfuscation since randomized strings of letters, numbers and special characters are very common. In its unaltered form, the n-gram space from which the models are built is likely too sparse to be useful. Inspired by recent research, a potential solution to this problem is to introduce what is known as composite word-type. This is a mapping of the original n-gram space onto a much smaller and more abstract n-gram space. Concretely, the idea is to have a predefined set of several classes into which possible characters or character sequences can fall. Consider this string of JavaScript code as a demonstrative example:
var x = 5;
A naïve character-level unigram formation of this statement would look like this:
[‘v’, ‘a’, ‘r’, ‘ ‘, ‘x’, ‘ ‘, ‘=’, ‘ ‘, ‘5’, ‘;’]
Alternatively, one could define classes, such as whitespace, individual keywords, alphanumeric, digit, punctuation, etc., to reduce this level of randomness. Using those classes, the unigram formation would look like this:
[‘var’, ‘whitespace‘, ‘alphanumeric’, ‘whitespace‘, ‘punctuation’, ‘whitespace‘, ‘digit’, ‘punctuation’]
Notice that the randomness has been significantly reduced in this new space. Many possible statements, which would all look very different from the perspective of a character-level unigram, could all fit into the above abstraction. All the possible fits to the abstraction have their underlying meaning expressed while ignoring ad hoc randomness. This increases the difficulty for malicious developers to undermine the detection system since this is very robust to string randomization and variance in general.
It makes sense to have a unique class for each JavaScript keyword since those are informative pieces of information that must occur in a standard form to compile. Other alphanumeric strings may also contain useful information, and thus it is not advisable to abstract away all instances into one class. Instead, you might make a list of predictive keywords you expect to find and add them as classes or derive them from the data itself. That is, count the number of occurrences of alphanumeric strings across malicious and benign scripts separately, and discover which strings have the largest difference in frequency between the two.
Shallow Dynamic Analysis
Despite the strong potential from static analysis, the problem is only alleviated, not completely solved. Benign, obfuscated samples are still under greater suspicion than is desirable. This is confirmed by the manual inspection of false positives, which are almost all obfuscated benign samples. The only way to completely overcome obfuscation is with dynamic analysis. A shallowly dynamic strategy generally known as deobfuscation includes a family of techniques used to evaluate and unpack obfuscated code back into its original form. More complex and dynamic analysis techniques exist that typically consist of tracking all actions taken by a script in an emulated browser environment. We won’t discuss those methods in this post, since we’re aiming to demonstrate that strong, dependable behavior can come from simpler, quicker methods.
There are many open source tools meant for JavaScript deobfuscation. Utilizing these tools as a pre-processing step on a script-by-script basis can ensure we generate features from strictly deobfuscated script. Of course, this changes the appearance of the data and demands either a new set of textual features or recomputed statistical language models. As mentioned before, a large increase in robustness is to be expected when working with deobfuscated script compared to obfuscated script. The verbosity and detail of each script is often greatly increased, which machine learning or language models can leverage to gain better insight and give better predictions.
Palo Alto Networks engineers help secure our way of life in the digital age by developing cutting-edge innovations for Palo Alto Networks Next-Generation Security Platform. Learn more about career opportunities with Palo Alto Networks Engineering.